Image by awcreativeut
I would appreciate
if you can subscribe to my YouTube Channel.
I know it's a big ask, but it will help me to keep writing and producing awesome content for you.
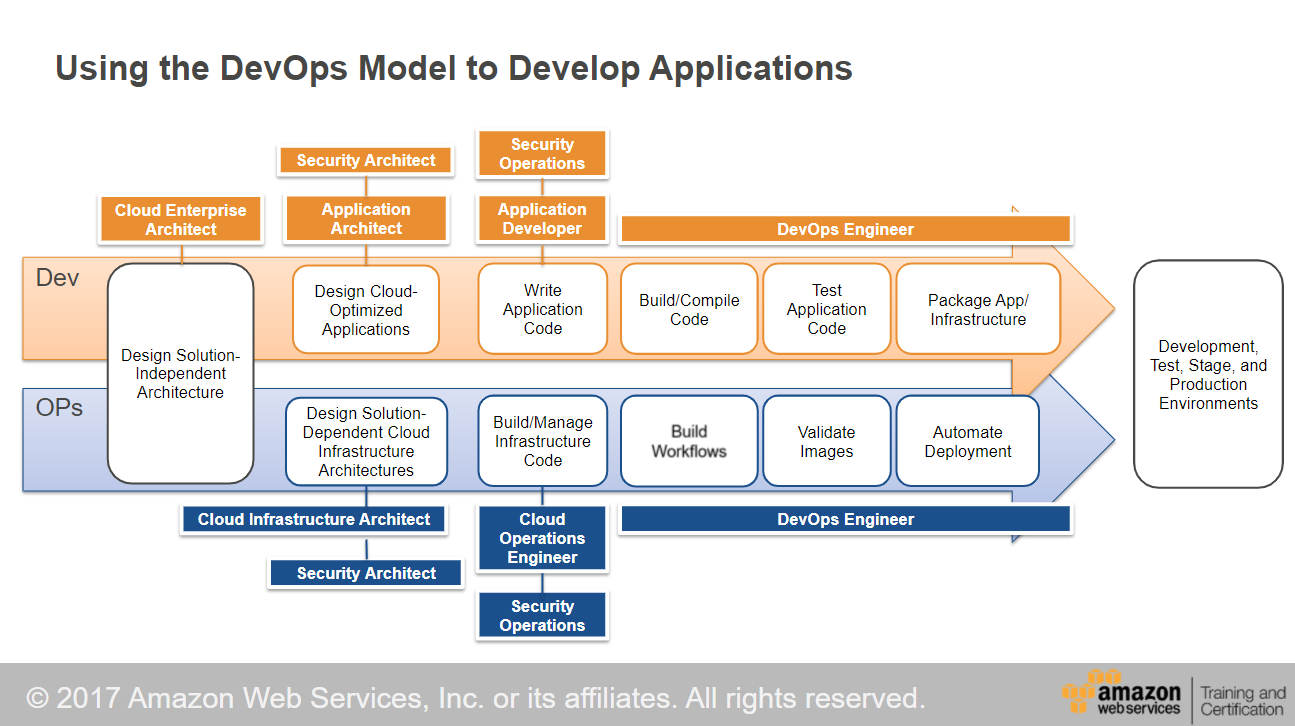
The word Host will repeatedly appear in the post so let's briefly understand what it means?
What is Host?
The Host is a container which offers rich built-in services such as Dependency Injection, Configuration, Logging, Host Services and others. The NET 6 offers Generic DefaultHost which can be configured to handle the activities as per your use case. Two major variations of the Host are:
- Console Host - CLI based applications.
- Web Host - Web API & Applications.
Think of it as Airbnb Host who keeps the property ready to serve when the guests arrive.
The property offers a different set of services and allows you to bring your own services. The lifetime of such services depends upon the contract, which the Host controls.
Basic Host Example : Create, configure, build, and run the Host
var host = Host.CreateDefaultBuilder(args)
.ConfigureLogging( (context, builder) => builder.AddConsole())
.Build();
await host.RunAsync();
What is Hosted Service?
A service that performs the work in the background mostly does not offer an interface to interact. In technical terms, any reference type object which implements the IHostedService interface is a background/hosted/worker service.
Terms such as Worker, Windows Service, and Background Task refer to HostedService based on context.
In Windows Server, Widows Service is how you deploy a Hosted Service. Background Task or Hosted service runs as part of .NET Web Host, and it runs in the same operating system process.